Falsification
Karl Popper
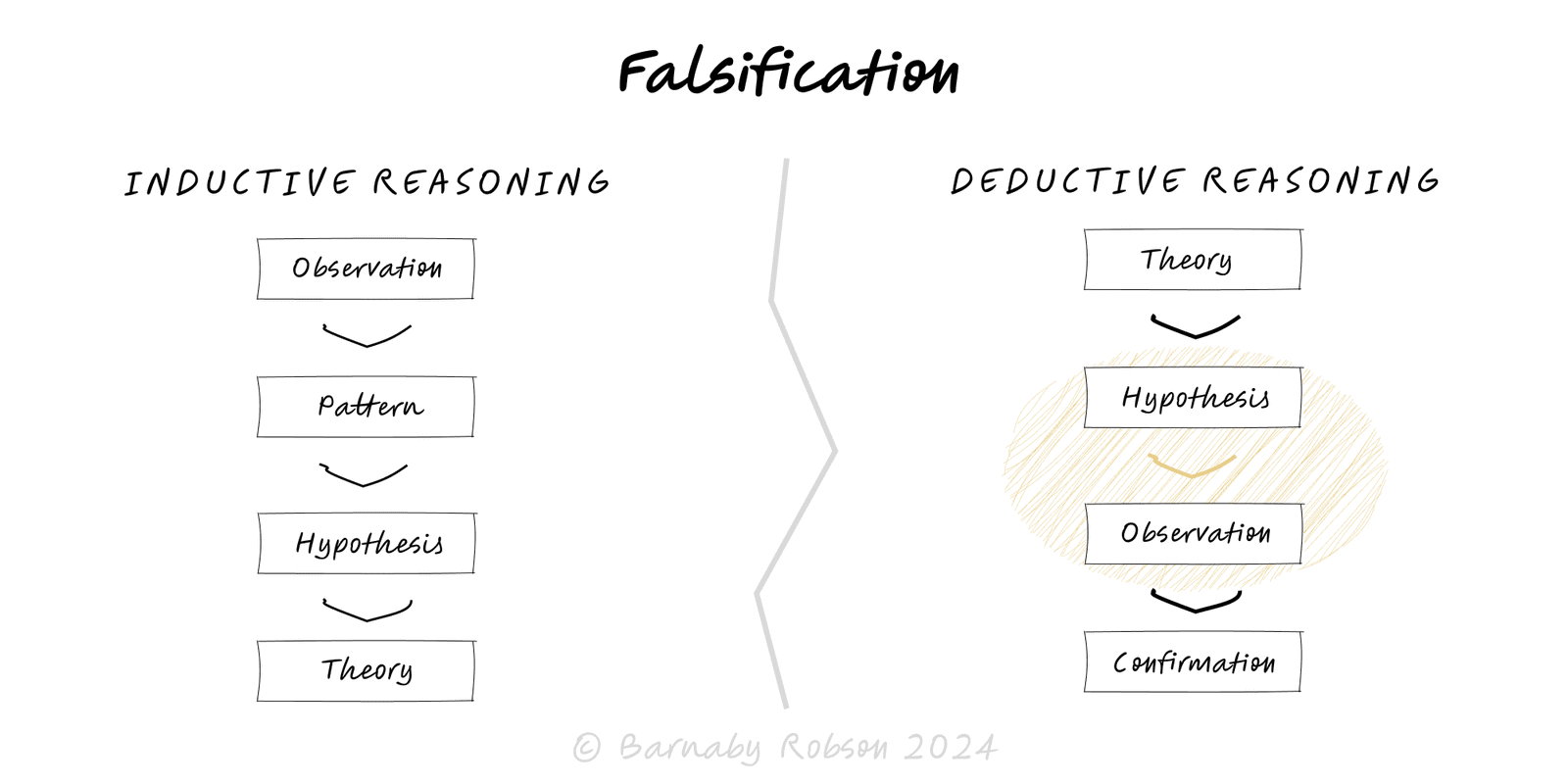
Popper’s falsification principle solves the “what counts as science” problem. Instead of looking for confirmations, you make risky predictions that your hypothesis would fail if it were wrong. The harder the test and the more chances to fail, the more weight you give to what survives.
Falsifiable statement – specifies what outcome would contradict it.
Risky prediction – excludes many possible outcomes, not just vague support.
Auxiliaries – measurement tools and assumptions must be stated so failure is interpretable.
Update or kill – if the prediction fails, fix the model or retire it; if it passes, increase confidence but do not treat it as proven.
Repeat and vary – independent replications under different conditions raise credibility.
Product and UX experiments.
Forecasting and strategy hypotheses.
Scientific and clinical trials.
Risk controls and incident playbooks.
Hiring and performance criteria.
Write the hypothesis in a form that could be wrong. Example: “Raising price by 10 percent will reduce conversion by at most 2 percent.”
State a disconfirming outcome before you test. Example: “If conversion falls by more than 2 percent (95 percent CI), we reject.”
Pre-register the plan – sample size, metric, analysis, and stop rules to prevent back-fitting.
Design the hardest fair test – clean control group, randomisation/blinding where possible, account for power.
Run once, analyse once – avoid peeking and multiple unplanned tests; correct if you must.
Decide using the rule you wrote – accept, adjust, or reject; record what changed and why.
Replicate – repeat on new cohorts, time periods, or segments to check robustness.
Unfalsifiable claims – statements that fit any outcome teach nothing. Rewrite them.
Ad hoc rescue – patching the story after bad results with new excuses. Pre-specify auxiliaries.
P-hacking and HARKing – data-mining or “hypothesising after results are known”. Use preregistration.
Underpowered tests – small samples fail to falsify anything. Plan for power and minimum detectable effect.
Single study worship – one pass is not proof; rely on replications and converging evidence.
Misread nulls – “no significant effect” is not proof of no effect; report intervals and minimum effects of interest.